
Decision Tree (Basic Intuition Entropy, Gini Impurity & Information Gain) NerdML YouTube
In information theory, the entropy of a random variable is the average level of "information", "surprise", or "uncertainty" inherent to the variable's possible outcomes. Given a discrete random variable , which takes values in the alphabet and is distributed according to , the entropy is. where denotes the sum over the variable's possible values.
What Is Entropy Definition, Equation and Formulas of Entropy
In the context of Decision Trees, entropy is a measure of disorder or impurity in a node. Thus, a node with more variable composition, such as 2Pass and 2 Fail would be considered to have higher Entropy than a node which has only pass or only fail. The maximum level of entropy or disorder is given by 1 and minimum entropy is given by a value 0.

Entropy How Decision Trees Make Decisions Towards Data Science
The P-V diagram of the Carnot cycle is shown in Figure 13.8.2 13.8. 2. In isothermal processes I and III, ∆U=0 because ∆T=0. In adiabatic processes II and IV, q=0. Work, heat, ∆U, and ∆H of each process in the Carnot cycle are summarized in Table 13.8.1 13.8. 1.

IAML7.5 Decision tree entropy YouTube
Rumus entropy jika dijabarkan secara tertulis adalah entropy = negatif jumlah dari atribut terhadap satu kelas atau label dikali log2 dalam kurung jumlah dari atribut terhadap satu kelas atau label ditambahkan lagi dengan rumus yang sama apabila jumlah kelas/labelnya lebih dari satu.Jika kelas atau labelnya ada 3 maka rumus entropy dijumlahkan 2 kali.
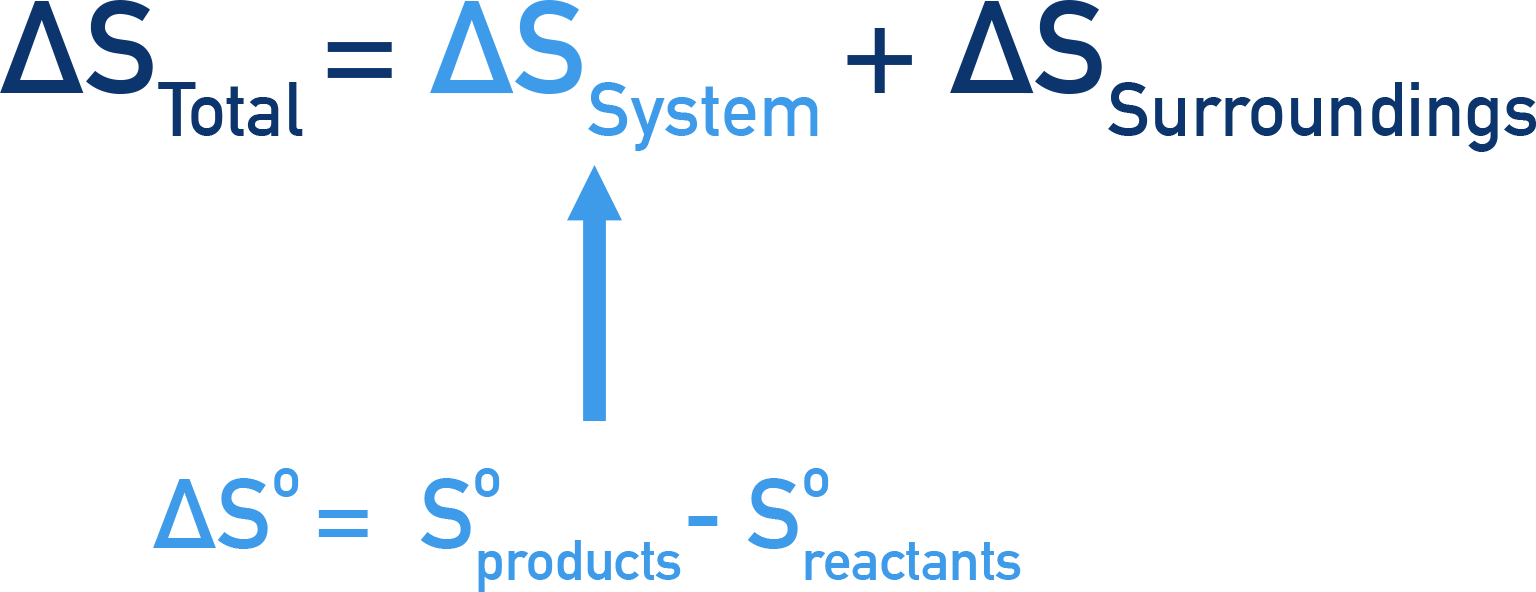
Total Entropy (ALevel) ChemistryStudent
Cross-entropy loss refers to the contrast between two random variables. It measures the variables to extract the difference in the information they contain, showcasing the results. Before going into detail, however, let's briefly discuss loss functions. We separate them into two categories based on their outputs:

Chain Rule of Entropy
Cross-entropy is commonly used in machine learning as a loss function. Cross-entropy is a measure from the field of information theory, building upon entropy and generally calculating the difference between two probability distributions. It is closely related to but is different from KL divergence that calculates the relative entropy between two probability distributions, whereas cross-entropy

Contoh 3 Rumus Entropi dan Penjelasannya
The degree to which a system has no pattern is known as entropy. A high-entropy source is completely chaotic, is unpredictable, and is called true randomness. Entropy is a function "Information" that satisfies: where: p1p2 is the probability of event 1 and event 2 p1 is the probability of an eventtwo classkhanacademy information-entropy.

Mechanical Engineering Thermodynamics Lec 10, pt 1 of 2 Entropy Balance YouTube
The Gini Index and the Entropy have two main differences: Gini Index has values inside the interval [0, 0.5] whereas the interval of the Entropy is [0, 1]. In the following figure, both of them are represented. The gini index has also been represented multiplied by two to see concretely the differences between them, which are not very significant.
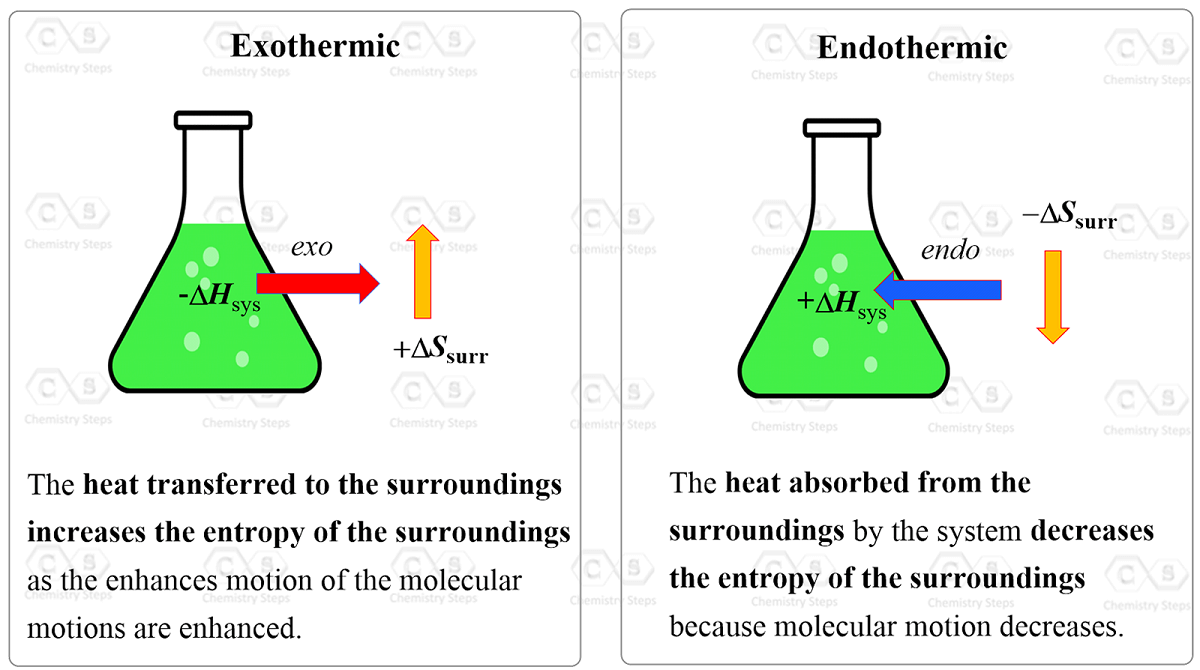
Entropy Changes in the Surroundings Chemistry Steps
Binary Cross-Entropy / Log Loss. where y is the label (1 for green points and 0 for red points) and p(y) is the predicted probability of the point being green for all N points.. Reading this formula, it tells you that, for each green point (y=1), it adds log(p(y)) to the loss, that is, the log probability of it being green.Conversely, it adds log(1-p(y)), that is, the log probability of it.
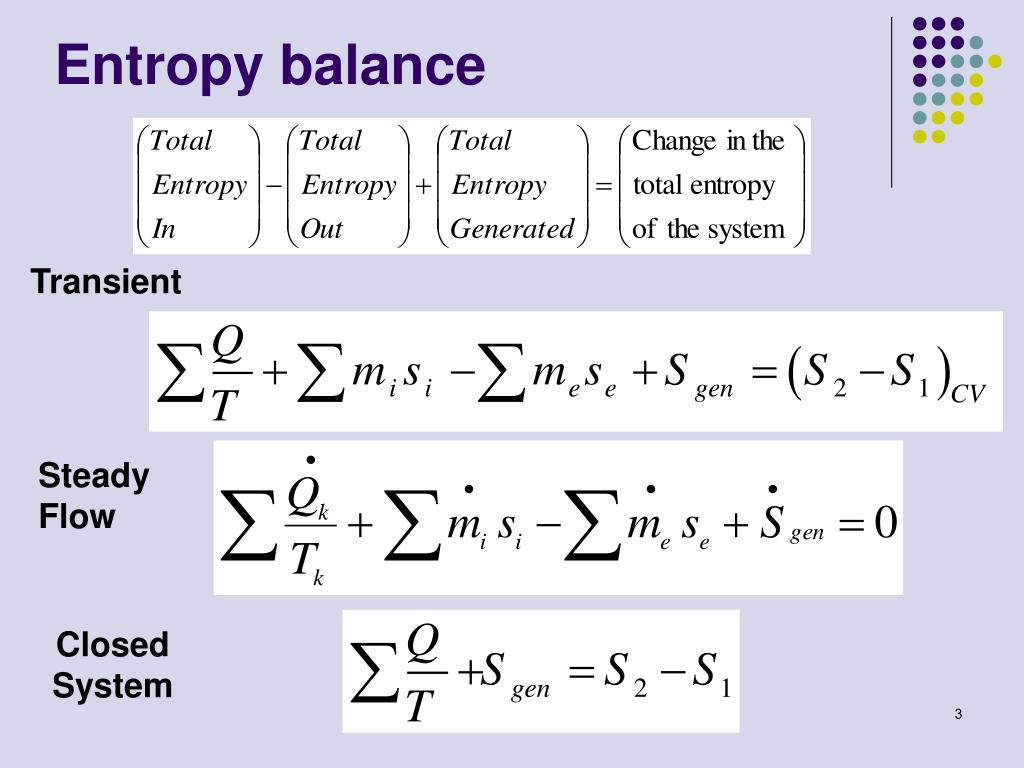
PPT Entropy balance for Open Systems PowerPoint Presentation ID545550
Mathematically, this means placing the lowest-entropy condition at the top such that it may assist split nodes below it in decreasing entropy. Information gain and relative entropy, used in the training of Decision Trees, are defined as the 'distance' between two probability mass distributions p(x) and q(x). It's also known as Kullback.

Entropy Equation & Calculations Lesson
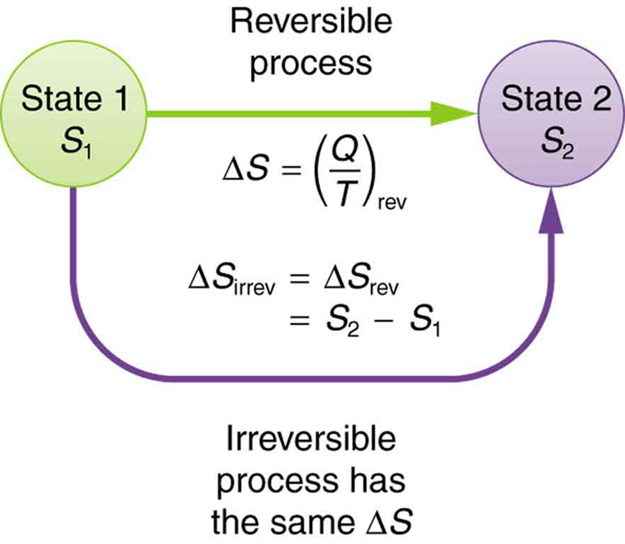
Clausius theorem. The Clausius theorem (1855), also known as the Clausius inequality, states that for a thermodynamic system (e.g. heat engine or heat pump) exchanging heat with external thermal reservoirs and undergoing a thermodynamic cycle, the following inequality holds. where is the total entropy change in the external thermal reservoirs.
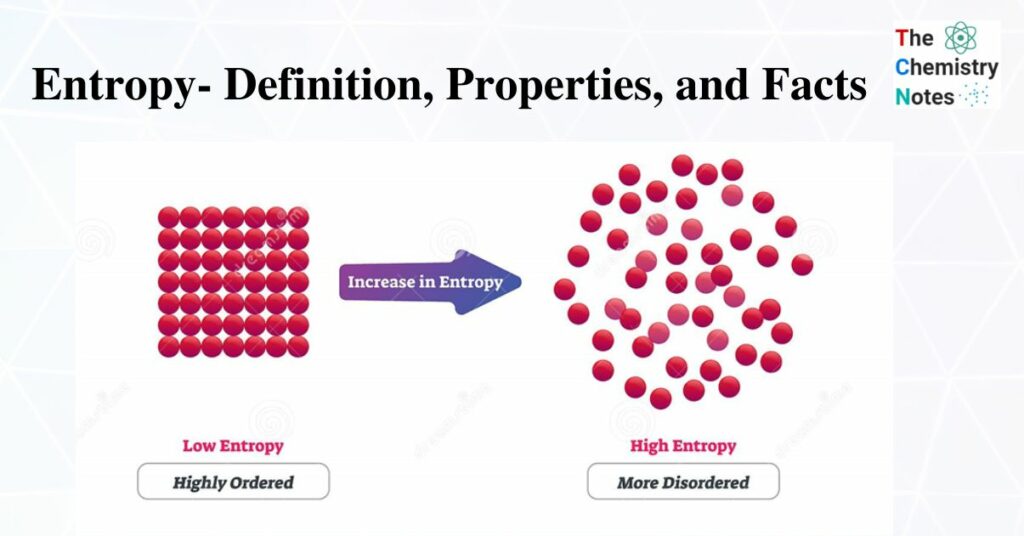
Entropy Definition, Properties, and Facts
See next Binary Cross-Entropy Loss section for more details. Logistic Loss and Multinomial Logistic Loss are other names for Cross-Entropy loss. The layers of Caffe, Pytorch and Tensorflow than use a Cross-Entropy loss without an embedded activation function are: Caffe: Multinomial Logistic Loss Layer. Is limited to multi-class classification.

What Is Entropy? Definition and Examples
Gini index is measured by subtracting the sum of squared probabilities of each class from one, in opposite of it, information gain is obtained by multiplying the probability of the class by log ( base= 2) of that class probability. Gini index favours larger partitions (distributions) and is very easy to implement whereas information gain.

Entropy Teori Informasi dan Perhitungan Manualnya YouTube
Entropy is introduced in thermodynamic system from physics. It then be used in many fields, including statistical mechanics, biology, and information theory. In machine learning, we use entropy.
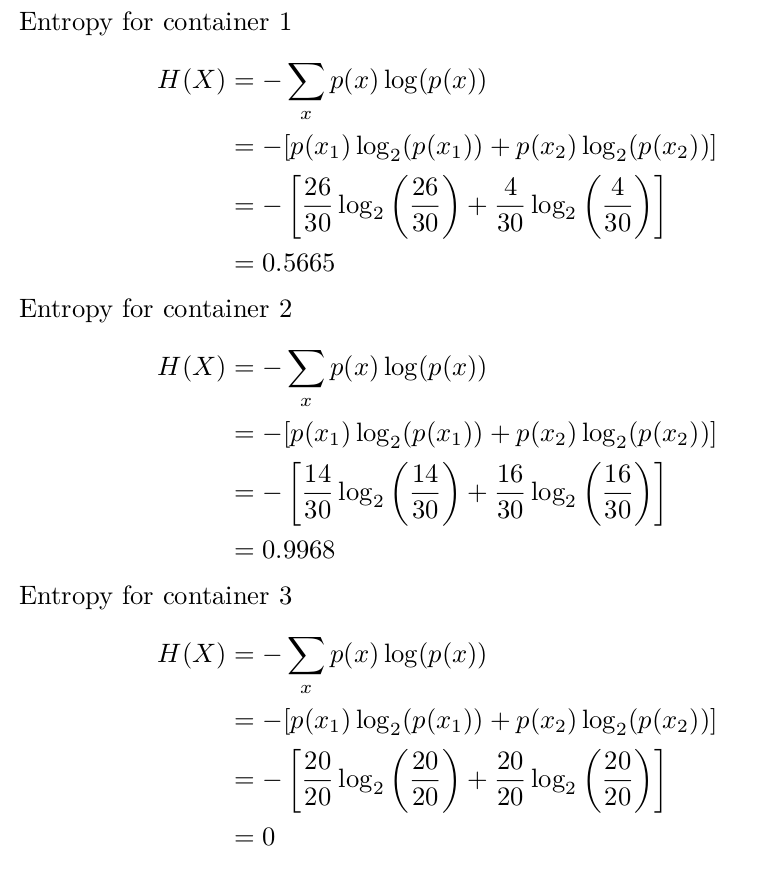
CrossEntropy Loss Function. A loss function used in most… by Kiprono Elijah Koech Towards
Binary Cross Entropy, also known as Binary Log Loss or Binary Cross-Entropy Loss, is a commonly used loss function in machine learning, particularly in binary classification problems. It is designed to measure the dissimilarity between the predicted probability distribution and the true binary labels of a dataset.

Lecture materials on introduction to Entropy and second law
Information Gain = how much Entropy we removed, so. \text {Gain} = 1 - 0.39 = \boxed {0.61} Gain = 1 −0.39 = 0.61. This makes sense: higher Information Gain = more Entropy removed, which is what we want. In the perfect case, each branch would contain only one color after the split, which would be zero entropy!