
Clustering in Data Mining Algorithms of Cluster Analysis in Data
What is clustering analysis? C lustering analysis is a form of exploratory data analysis in which observations are divided into different groups that share common characteristics.. The purpose of cluster analysis (also known as classification) is to construct groups (or classes or clusters) while ensuring the following property: within a group the observations must be as similar as possible.
Types of Clustering 5 Awesome Types of Clustering You Should Know
Hierarchical Clustering Hierarchical clustering in data mining is a method that builds a tree-like hierarchy of clusters, either by merging smaller clusters into larger ones (agglomerative or bottom-up) or by splitting larger clusters into smaller ones (divisive or top-down). It does not require a pre-defined number of clusters.

Clustering Algorithms in Machine Learning Clusterting in ML
Centroid-based clustering organizes the data into non-hierarchical clusters, in contrast to hierarchical clustering defined below. k-means is the most widely-used centroid-based clustering algorithm. Centroid-based algorithms are efficient but sensitive to initial conditions and outliers. This course focuses on k-means because it is an.

Figure 1 from AN OVERVIEW OF CLUSTERING ALGORITHM IN DATA MINING
A. Agglomerative clustering is a popular data mining technique that groups data points based on their similarity, using a distance metric such as Euclidean distance. Different distance measures can be used depending on the type of data being analyzed. It is a bottom-up approach that merges similar clusters iteratively, and the resulting.

Clustering Algorithms in Data Mining Meaning DataTrained Data
1) Clustering Data Mining Techniques: Agglomerative Hierarchical Clustering. There are two types of Clustering Algorithms: Bottom-up and Top-down. Bottom-up algorithms regard data points as a single cluster until agglomeration units clustered pairs into a single cluster of data points. A dendrogram or tree of network clustering is employed in.

What is Clustering in Data Mining? 6 Modes of Clustering in Data Mining
Cluster analysis can also be used to perform dimensionality reduction(e.g., PCA). It might also serve as a preprocessing or intermediate step for others algorithms like classification, prediction, and other data mining applications. ⇨ Types of Clustering. There are many ways to group clustering methods into categories.
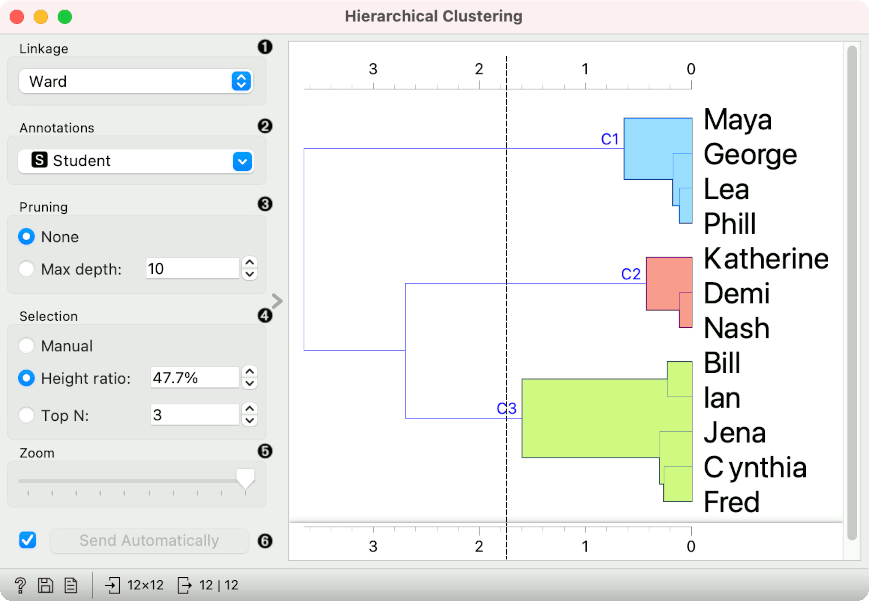
Orange Data Mining Hierarchical Clustering
Cluster analysis, also known as clustering, is a method of data mining that groups similar data points together. The goal of cluster analysis is to divide a dataset into groups (or clusters) such that the data points within each group are more similar to each other than to data points in other groups. This process is often used for exploratory.

(PDF) Customer Data Clustering Using Data Mining Technique
Requirements of clustering in data mining: The following are some points why clustering is important in data mining. Scalability - we require highly scalable clustering algorithms to work with large databases. Ability to deal with different kinds of attributes - Algorithms should be able to work with the type of data such as categorical.
Clustering in Data Mining Algorithms of Cluster Analysis in Data
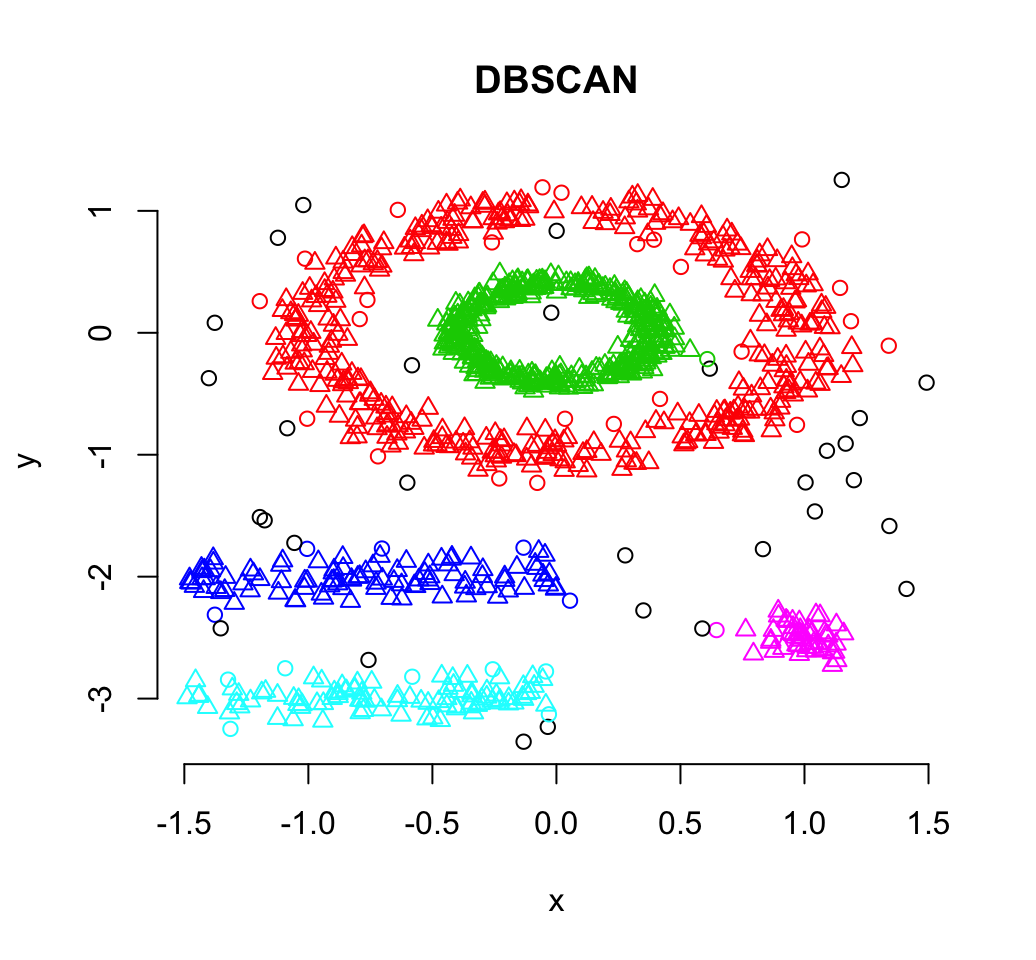
In this method of clustering in Data Mining, density is the main focus. The notion of mass is used as the basis for this clustering method. In this clustering method, the cluster will keep on growing continuously. At least one number of points should be there in the radius of the group for each point of data. 4.
Understanding data mining clustering methods Subconscious Musings
The DENCLUE (Density Clustering) algorithm is a density-based clustering technique that determines clusters based on the local density attractors, representing local maxima in an overall density function. It employs an influence function to calculate the distance between data points, and the density function is the cumulative sum of these.
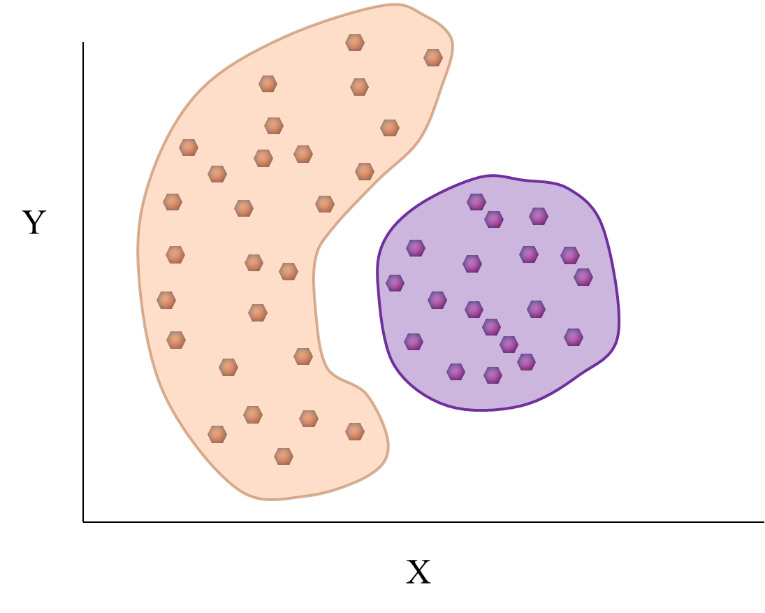
Understanding data mining clustering methods Subconscious Musings
Summary. Cluster analysis is a powerful technique for grouping data points based on their similarities and differences. In this guide, we explore the top data mining tools for cluster analysis, including K-means, Hierarchical clustering, and more. We look at an overview of the benefits and applications of cluster analysis in various industries.

Clustering in Data mining K means Clustering Algorithm Hierarchical
1. Introduction. Clustering (an aspect of data mining) is considered an active method of grouping data into many collections or clusters according to the similarities of data points features and characteristics (Jain, 2010, Abualigah, 2019).Over the past years, dozens of data clustering techniques have been proposed and implemented to solve data clustering problems (Zhou et al., 2019.

Data Mining Clustering YouTube
Machine learning systems can then use cluster IDs to simplify the processing of large datasets. Thus, clustering's output serves as feature data for downstream ML systems. At Google, clustering is used for generalization, data compression, and privacy preservation in products such as YouTube videos, Play apps, and Music tracks.
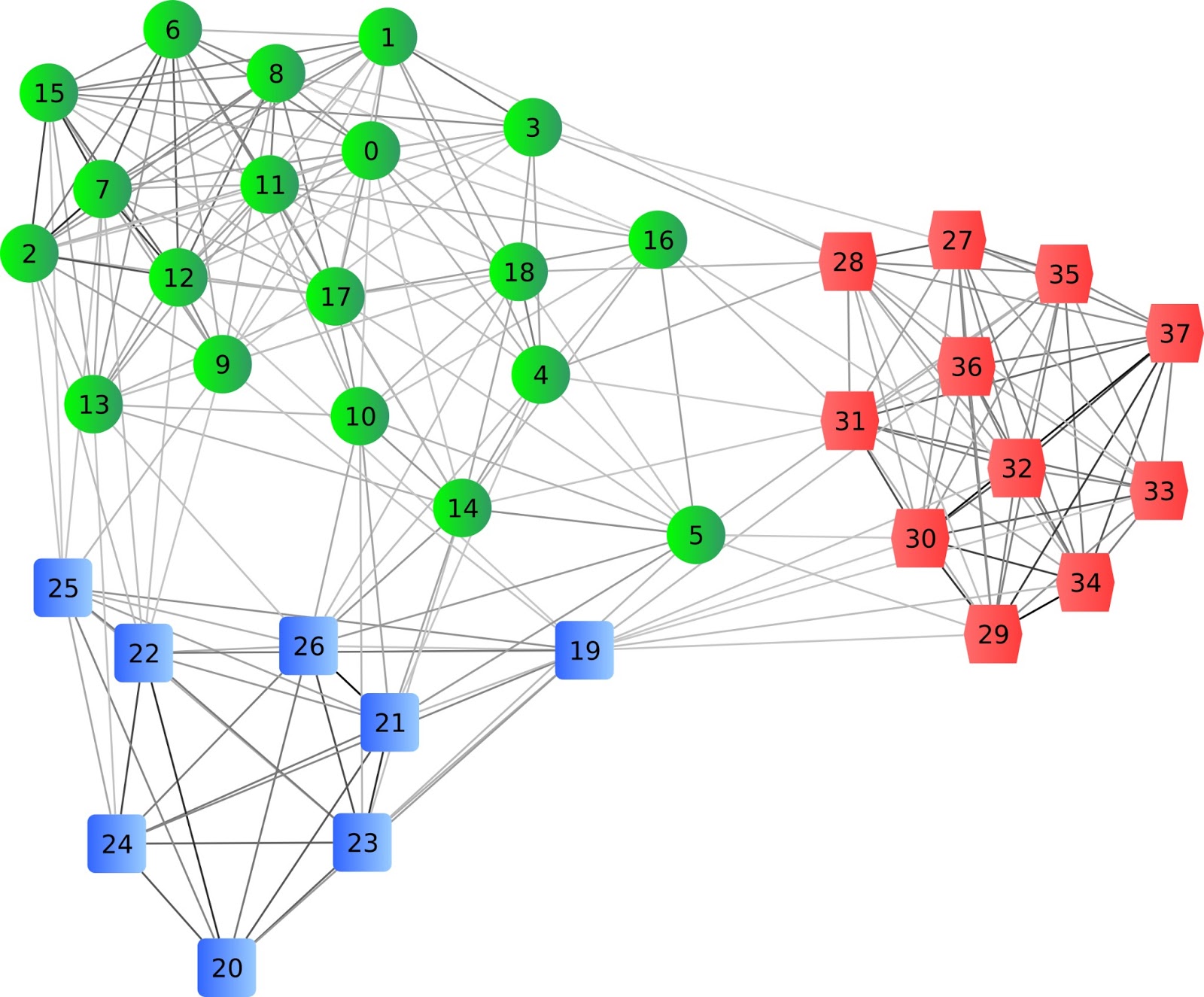
Analytics and Visualization of Big Data Distancebased clusterings
Cluster analysis or clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some specific sense defined by the analyst) to each other than to those in other groups (clusters). It is a main task of exploratory data analysis, and a common technique for statistical data analysis, used in many fields, including.
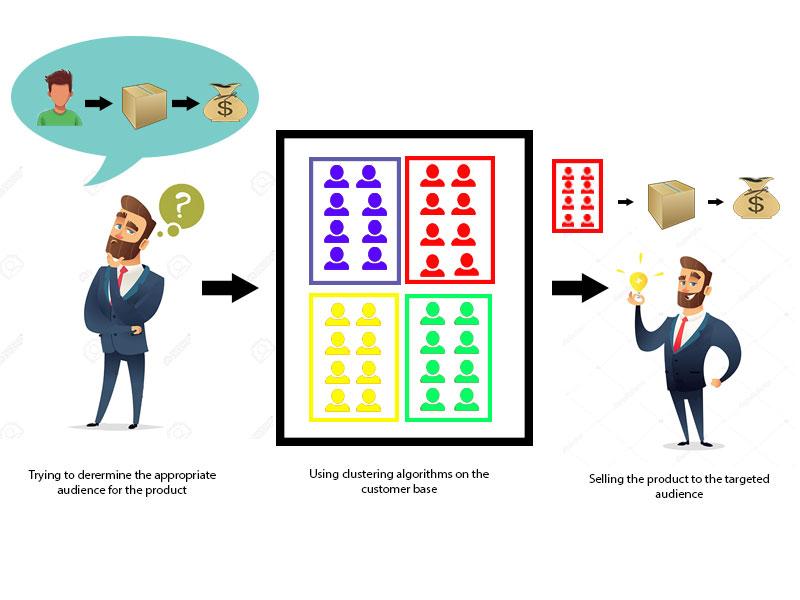
Data Mining Cluster Analysis Javatpoint
Next, let's understand two main data mining tasks and in which category the clustering comes. Data mining tasks . Figure 2: Data mining tasks. The two main data mining tasks consists of: Predictive Methods: This method uses some variables to predict unknown values of other variables. It includes data mining task such as classification.

The 5 Clustering Algorithms Data Scientists Need to Know
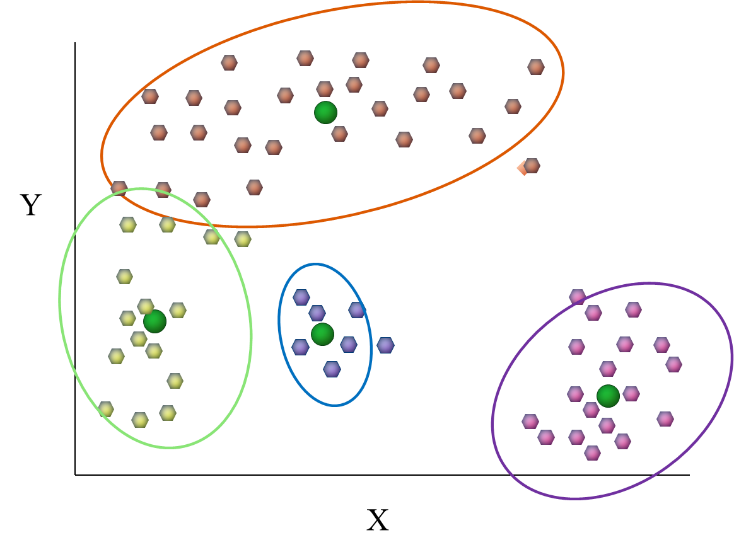
K-means clustering is the most commonly used clustering algorithm. It's a centroid-based algorithm and the simplest unsupervised learning algorithm. This algorithm tries to minimize the variance of data points within a cluster. It's also how most people are introduced to unsupervised machine learning.